Spring Reactive Programming: Asynchronous, Non-blocking, and Scalable Solutions
Before delving into reactive programming, it’s important to know the concept of a stream. A stream represents a sequence of data transmitted from one system to another, typically following a blocking, sequential, and FIFO (first-in-first-out) pattern. The conventional blocking nature of data streaming often hinders a system’s ability to process real-time data concurrently with streaming. Consequently, the concept of constructing a “reactive” systems architecture emerged to facilitate the seamless processing of data during streaming.
What is Reactive Programming and why is a need for Reactive Programming?
Reactive programming is a programming paradigm that helps to implement non-blocking, asynchronous, and event-driven or message-driven data processing. It models data and events as streams that it can observe and react to by processing or transforming the data. The term, “reactive,” refers to programming models that are built around reacting to changes. It is built around the publisher-subscriber pattern (observer pattern). In the reactive style of programming, we make a request for resources and start performing other things. When the data is available, we get the notification along with data in the callback function. The callback function handles the response as per application/user needs.
Most usual programs work in a way that if they’re busy, new tasks have to wait for their turn. This happens in traditional applications that use blocking or synchronous calls. When many threads are occupied, the program blocks new tasks until the ongoing ones are completed.
However, some modern applications need to handle multiple tasks at the same time. Reactive programming on the server side helps with this. It allows web or server applications to work more efficiently by handling multiple tasks simultaneously. This is done asynchronously, meaning the program doesn’t have to wait for one task to finish before starting another. This improves performance, makes the program more scalable, and better equipped to handle lots of users.
Difference between Blocking and Non-blocking request Processing.
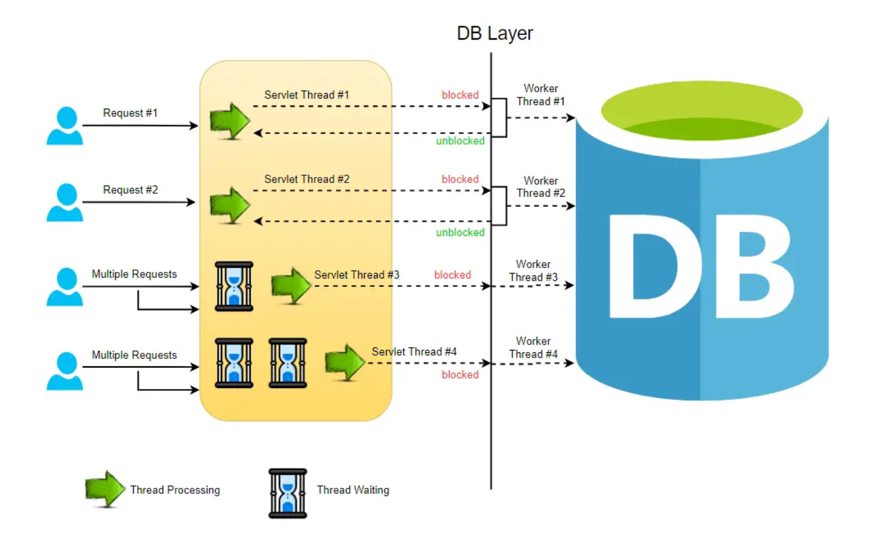
Blocking Request Model:
In a typical MVC application, when a request arrives at the server, a servlet thread is generated and assigned to worker threads for tasks such as I/O and database processing. While these worker threads are occupied with their tasks, the servlet threads go into a waiting state, causing the calls to be blocked. This process is known as blocking or synchronous request processing. Since a server has a finite number of request threads, it constrains the server’s ability to handle a maximum number of requests during peak loads. This limitation may impact performance and hinder the server from fully utilizing its capabilities.
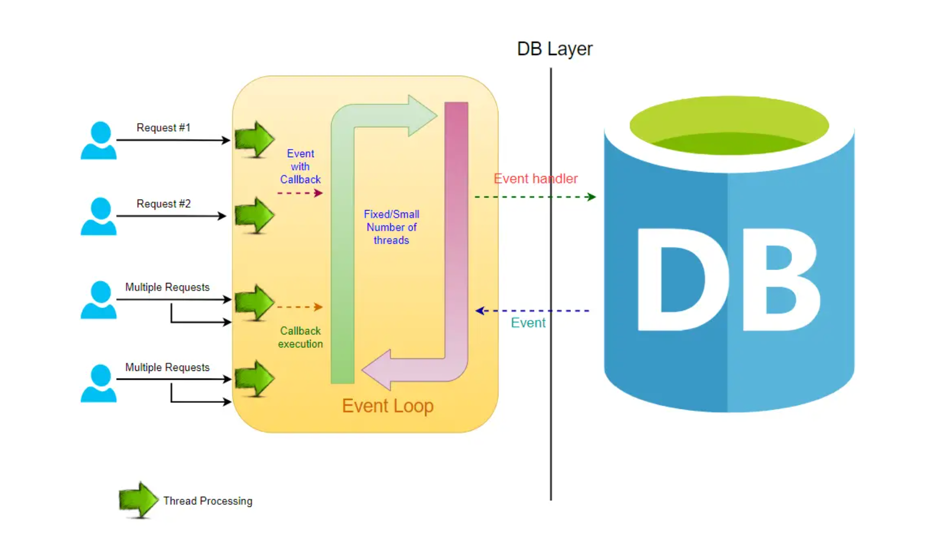
Non-blocking Request Model:
In a non-blocking system, every incoming request is accompanied by both an event handler and a callback. The request thread then delegates the incoming request to a thread pool, which efficiently manages a limited number of threads. Subsequently, the thread pool assigns the request to its handler function and becomes available to handle additional incoming requests from the request thread.
Upon completion of the handler function’s processing, one of the threads from the pool retrieves the response and forwards it to the callback function. Consequently, the threads in a non-blocking system never enter a waiting state, thereby enhancing the productivity and performance of the application.
In this non-blocking paradigm, a single request has the potential to be processed by multiple threads, contributing to the scalability of the application’s performance. The non-blocking nature of threads facilitates improved application performance, as the small number of threads leads to reduced memory utilization and minimizes context switching.
Components of Reactive Programming:
Reactive Streams was conceived with the aim of establishing a standard for asynchronous stream processing of data, incorporating non-blocking backpressure. To fulfill this objective, Java 9 introduced the Reactive Streams API.
- Publisher - It is responsible for preparing and transferring data to subscribers as individual messages. A Publisher can serve multiple subscribers but it has only one method, subscribe().
public interface Publisher<T> { public void subscribe(Subscriber<? super T> s); } - Subscriber - A Subscriber is responsible for receiving messages from a Publisher and processing those messages. It acts as a terminal operation in the Streams API. It has four methods to deal with the events received.
- onSubscribe(Subscription s) - Gets called automatically when a publisher registers itself and allows the subscription to request data.
- onNext(T t) - Gets called on the subscriber every time it is ready to receive a new message of generic type T.
- onError(Throwable t) - Is used to handle the next steps whenever an error is monitored.
- onComplete() - Allows to perform operations in case of successful subscription of data.
public interface Subscriber<T> { public void onSubscribe(Subscription s); public void onNext(T t); public void onError(Throwable t); public void onComplete(); } - Subscription: It represents a one to one relationship between the subscriber and publisher. It can be used only once by a single Subscriber. It has methods that allow requesting for data and to cancel the demand:
public interface Subscription { public void request(long n); public void cancel(); } - Processor: It represents a processing stage that consists of both Publisher and Subscriber.
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> { }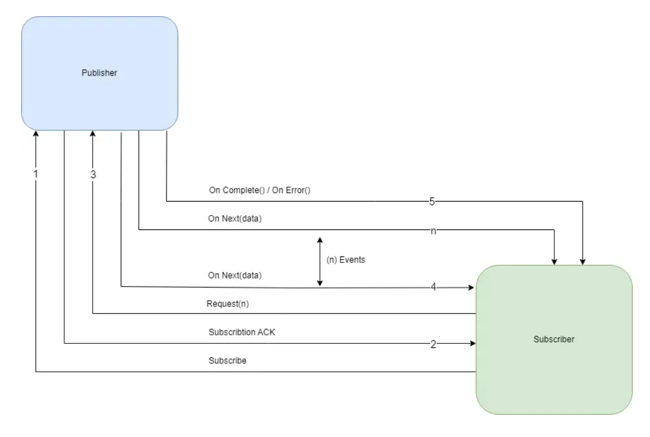
Spring Webflux
Spring WebFlux is a parallel version of Spring MVC and supports fully non-blocking reactive streams. It supports the back pressure concept and uses Netty as the inbuilt server to run reactive applications. It is built on Project Reactor library that makes it possible to build reactive applications on the HTTP layer.
Two publishers which are used heavily in webflux
- Mono: Returns 0 or 1 element.
Mono<String> mono = Mono.just("Sixt"); Mono<String> mono = Mono.empty(); - Flux: A Publisher that emits 0 to N elements which can keep emitting elements forever. It returns a sequence of elements and sends a notification when it has completed returning all its elements.
Flux<Integer> flux = Flux.just(1, 2, 3, 4); Flux<String> fluxString = Flux.fromArray(new String[]{"A", "B", "C"}); Flux<String> fluxIterable = Flux.fromIterable(Arrays.asList("A", "B", "C")); Flux<Integer> fluxRange = Flux.range(2, 5); Flux<Long> fluxLong = Flux.interval(Duration.ofSeconds(10)); flux.subscribe();The data won’t flow or be processed until the subscribe() method is called. log() method is used to trace and observe all the stream signals. The events are logged into the console.
To start with using Web Flux with spring boot below dependency should be added
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
<version>3.0.5</version>
</dependency>
Concept of Backpressure:
In Reactive Streams, backpressure establishes the mechanism for regulating the transmission of data across streams.
Imagine that server A dispatches 1000 EPS (events per second) to server B. However, server B can only handle 800 EPS, resulting in a shortfall of 200 EPS. As a consequence, server B faces the challenge of falling behind, needing to process the deficit data and transmit it downstream or possibly store it in a database. Consequently, server B grapples with backpressure, and there’s a risk of running out of memory and experiencing failure.
To address this backpressure scenario, several options or strategies can be employed:
- Buffer - The deficit data can be buffered for later processing when the server has the capacity. But with a huge load of data coming in, this buffer might increase and the server would soon run out of memory.
- Drop - Dropping, i.e. not processing events, should be the last option. Usually, we can use the concept of data sampling combined with buffering to achieve less data loss.
- Control - The concept of controlling the producer that sends the data is by far the best option. Reactive Streams provides various options in both push and pull-based streams to control the data that is being produced and sent to the consumer.
Backpressure ensures that both producers and consumers can operate at their optimal processing rates, preventing bottlenecks or system overload.
@GetMapping(produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<UserResponse> retrieveUsers() {
return userService.retrieveUsers()
.onBackpressureBuffer(10, BufferOverflowStrategy.DROP_OLDEST)
.delayElements(Duration.ofMillis(100))
.log();
}
The onBackpressureBuffer(10, BufferOverflowStrategy.DROP_OLDEST) operator is then applied to the Flux, which limits the buffer size to 10 elements and uses a buffer overflow strategy of dropping the oldest elements when the buffer becomes full. This means that if the downstream subscriber cannot keep up with the rate of emissions, the buffer will store up to 10 elements before it starts dropping older elements to make room for newer ones. The delayElements(Duration.ofMillis(100)) operator is applied to the Flux, which adds a delay of 100 milliseconds before emitting each element. This means that the UserResponse objects emitted by the Flux will be spaced out by at least 100 milliseconds, which can help control the rate of emissions and prevent backpressure issues.
One of the best examples of backpressure in a streaming service context is managing the flow of data between a content provider (such as Netflix) and a client (such as a user’s device) during video streaming. In video streaming, the server needs to send video data to the client continuously to maintain uninterrupted playback. However, the client’s ability to receive and process this data can vary due to factors like network congestion, device capabilities, or the user’s internet connection. Benefits:
Smooth Playback: By employing backpressure mechanisms, Netflix ensures smooth playback for users by dynamically adjusting the delivery of data based on network conditions and device capabilities.
Efficient Resource Utilization: Backpressure helps Netflix optimize the utilization of its streaming infrastructure, preventing overload on servers, CDNs, and network components.
Improved User Experience: By mitigating buffering and playback issues, backpressure contributes to a better overall user experience, leading to higher customer satisfaction and retention.
Use cases of Reactive Programming
Reactive web programming is particularly useful for applications that involve streaming data and real-time interactions. It uses methods that don’t block the program, making it responsive to changes without delay.
-
High-Concurrency Web Applications: Applications that require handling a large number of concurrent connections, such as real-time messaging systems, chat applications, or multiplayer online games, can benefit from Spring WebFlux. It allows handling many requests with a small number of threads, leading to efficient resource utilization and scalability.
-
Streaming Data and Media: Applications that deal with streaming data, such as audio/video streaming platforms, real-time analytics, or IoT data processing, can leverage Spring WebFlux. It supports handling continuous streams of data with backpressure mechanisms, ensuring that data processing is efficient and responsive.
-
Event-Driven Applications: Applications that are event-driven, where actions are triggered based on events or messages, can utilize Spring WebFlux to handle event streams efficiently. This includes applications like real-time notifications, event sourcing systems, or reactive workflows where responsiveness and real-time processing are critical.
-
Internet of Things (IoT) and Edge Computing: In IoT scenarios where devices generate continuous streams of data, and in edge computing environments where resources are limited, Spring WebFlux can be used to build reactive applications that handle data streams efficiently and can scale based on demand.
Limitations of Reactive Programming
- Complexity:
- Learning Curve: Reactive programming introduces new paradigms and abstractions, which can be challenging for developers accustomed to imperative programming.
- Debugging and Tracing: Reactive code can be harder to debug and trace due to its asynchronous nature, making it difficult to pinpoint the source of issues.
- Tooling and Ecosystem:
- Limited Tool Support: Compared to traditional Spring MVC, tooling and ecosystem support for WebFlux is less mature, which might limit debugging, profiling, and performance tuning capabilities.
- Integration Challenges: Integrating WebFlux with other libraries or frameworks that are not designed for reactive programming can be challenging.
- Limited Use Cases:
- Not Always Beneficial: For applications with low concurrency requirements or that are primarily CPU-bound, the benefits of a reactive model may not justify the added complexity.
- Suitability: Reactive programming is particularly beneficial for I/O-bound applications. For other types of applications, the traditional blocking model might be more straightforward and efficient.
- Library and Framework Compatibility:
- Blocking Libraries: Many existing Java libraries are blocking and may not work well with WebFlux, requiring careful selection or modification of libraries.
- Backpressure Handling: Properly handling backpressure (the situation where producers generate data faster than consumers can process) requires careful design and is not always straightforward.
- Scalability Concerns:
- Thread Pool Management: Managing thread pools effectively in a reactive system is crucial and can be complex. Poorly managed thread pools can negate the scalability benefits of a non-blocking approach.
- Resource Management: Reactive applications need careful resource management to avoid potential bottlenecks and ensure optimal performance.
While WebFlux offers significant advantages for building scalable, non-blocking applications, it is essential to weigh these disadvantages and consider whether it is the right fit for your specific use case and team expertise.
Conclusion
Reactivity and non-blocking behavior typically don’t enhance the speed of applications directly. Instead, the anticipated advantage lies in the capacity to scale the application efficiently using a limited, constant number of threads and reduced memory demands. This scalability feature contributes to enhanced resilience under heavy loads, ensuring a more predictable scaling pattern for applications.